
End-users constantly make GET or POST request to the internet to retrieve information. The most common protocol used here is HTTP/S. But this communication is not just about making requests. It needs to be meaningful when sent from client to server or vice-versa. Here’s when HTTP header comes in. With headers, client/server can send additional information with HTTP request.
In this blog post, I will be covering some of the basic headers that you really need to know about. Later in the post, I’ll be listing about a few more headers that you would indeed find while performing any pentest or bug bounty hunting. Having a crisp knowledge can aid you in exploiting web applications just based on headers. Exciting right???
Let’s dive in and fathom each of them.
There are 4 types of HTTP header.
- General-header: header fields that can be used with both the request and response messages..
- Client Request-header: These header fields can only be used with request messages.
- Server Response-header: These header fields can only be used with response messages.
- Entity-header: These header fields define meta-information about the entity-body. If no body is present, it provides about the resource identified by the request.
Let’s discuss them!
Client Request Headers
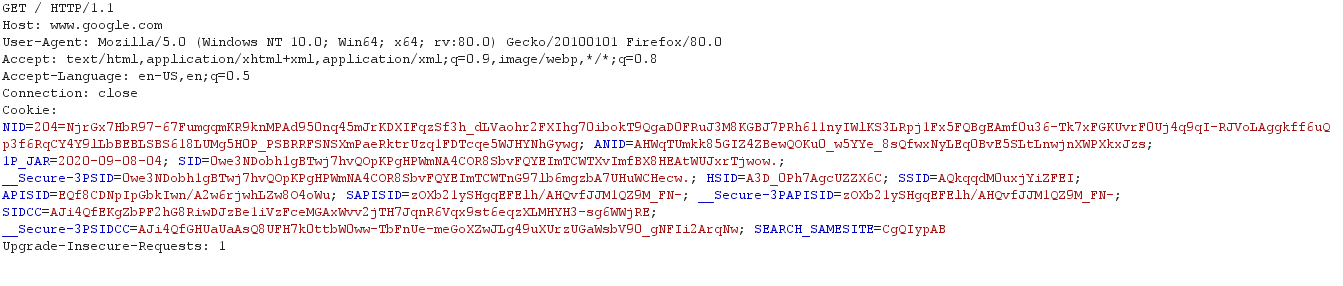
The first line of any request is as follows
GET / HTTP/1.1
Here GET is the HTTP verb of the request. THere are other HTTP verbs available like PUT, POST, OPTIONS, DELETE.
/ is the path. Path tells the server which resource the browser is asking for.
HTTP/1.1 tells about the protocol and the protocol version. Protocol version tells how to communicate with the browser.
Host header field
The next header field that can be seen in the screenshot is the Host header field. It is represented by:
Host: www.google.com
This field specifies the internet hhostname and the port number of the resource being requested.
User-Agent
This is represented by:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0
It tells the server what client software is using to request the resource. It also reveals the client’s OS
Accept header field
Represented by:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Browser sends this field to the server to specify what type of document it is expecting in the response. In the above example, browser can accept html, xhtml, xml, webp.
Accept-Encoding header field
Represented as:
Accept-Encoding: gzip, deflate
It works similar to Accept but restricts the content encoding. In the above example, browser supports 2 types of compression techniques namely:
gzip
deflate
Connection header filed
Represented as:
Connection: close
This field allows the sender to specify options that are desired for that particular connection. There is one another directive available that is [ Connection: keep-alive ].
Close directive indicates that either the client or the server would close the connection. Keep-alive directive indicates that the client would like to keep the connection open. This is used for making persistent connections. Keep-alive is also a default directive in HTTP/1.1
The headers discussed above were the most basic ones. But its important to know the how exactly it works.
Now I’ll be talking of few more headers that are used a lot in ctf challenges or you can encounter such scenarios in your pentest career. Let’s dive in
X-Forwarded-For header
X-Forwarded header which is used when a client connects to a web server through an HTTP proxy or load balancer for identifying the original IP address. Sometimes, the privacy of the user might be at risk as usage of this header can reveal sensitive information.
Representation:
X-Forwarded-For: 103.0.113.165, 60.91.3.17, 120.192.338.678
In this example the request has to go through multiple proxies.
X-Forwared-For: X.X.X.X
Has to go through single proxy only
X-Forwarded-For header can be used at times to bypass the rate limiting enfored on login panel/ forget-password.
In the request, add a line: X-forwarded-For: 127.0.0.1 and every time rate limit is reached, change the IP to something like 127.0.0.2 and so on.
Referer header
This header contains the absolute or partial address of the page making a request. For example when i search for anything on google.com, the referrer header will have https://google.com [as the request was initiated by this page]
Simply put, its just the sequence of request that you make. It can be multi-domain request too.
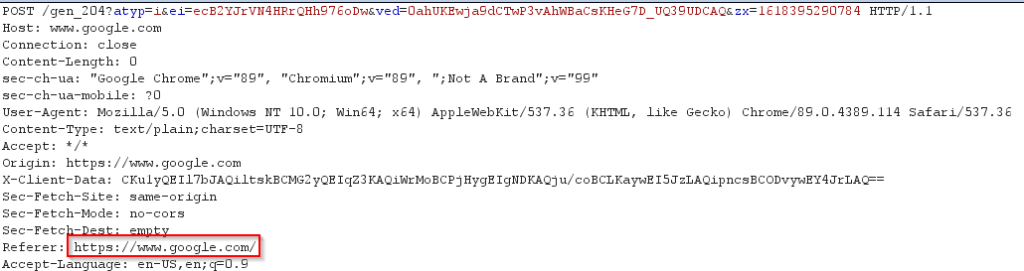
The problem with referrers
For example you want to reset the password. You receive a reset link on you mail and you paste in on the browser and hit enter. Now you make another request to https://evil.com. Now the referrer header will have address of the reset link that might contain some sensitive information. This information is now being leaked to attacker. Read more about it here
HTTP RESPONSE HEADERS
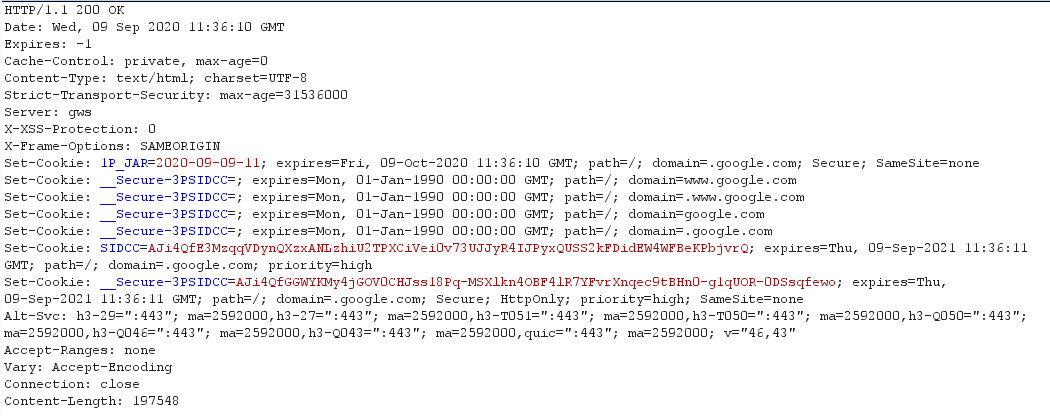
The above screenshot determines how a typical response looks like. Since we had requested google.com, the reponse obtained has a lot of headers. Large MNCs known for its high-end security usually implement all those headers to stay safe from the adversaries. Here I will discuss the most commonly used headers.
HTTP/1.1 200 ok
The first line clearly describes the protocol version as discussed above. 200 ok is the response code. 200 Means that the response is successfully obtained from the server. Response codes are a way for telling the client about the behaviour of the server when a request is made. There are numerous HTTP codes which determines a certain meaning.
Cache-Control header
Represented as:
Cache-Control: private, max-age=0
Using cached content saves bandwidth, as it prevents the client from re-requesting unmodified content.
Cache-Control: max-age=<seconds>Cache-Control: max-stale[=<seconds>]Cache-Control: min-fresh=<seconds>Cache-Control: no-cacheCache-Control: no-storeCache-Control: no-transformCache-Control: only-if-cached
Read more about the specific keywords here :- https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control
Set-Cookie header
Different formats of cookie
Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>; Secure; HttpOnly Set-Cookie: sessionId=e8bb43229de9; Domain=foo.example.com Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT
Set-cookie header is used to send cookie to the user agent so that it can use the same cookie in future communications.
This header has various important attributes.
<cookie-name>=<cookie-value> . It follows the concept of key value pair.
<Expires>=<date> The maximum lifetime of the cookie as an HTTP-date timestamp.
<Path>=path A path that must exist in the requested URL, or the browser won’t send the Cookie header.
Secure: A secure cookie is only sent to the server when a request is made with the https: scheme
HttpOnly: When a server installs a cookie into a client with the http-only attribute, the client will set the http-only flag for the cookies. This mechanism prevents JS, flash, java and non-html technology from reading the cookie. Henceforth, it prevents cookie stealing via XSS.
Read more about how to add headers in requests made via scripts
Session ID
Sometimes web developer prefers to store some information on the server-side instead of the client-side. The reason can either to hide the application logic or to just avoid back-forth transmission of cookies. To get rid of all those problems, Sessionid can be used. It is a unique identifier. Everytime when browser makes a http request, this identifier is sent to the server.
By means of session id, the server retrieves the state of the client. Session IDs are stored in text files on the client-side.
Headers corresponding to the origin policy
Origin Request headers
Representation
Origin: https://example.com
This header indicates about the server from where the fetch originates. Unlike, referrer header, it does not disclose the whole path.
Origin Response Headers
Access-Control-Allow-Origin header
Representation
Access-Control-Allow-Origin: * Access-Control-Allow-Origin: https://example.com Access-Control-Allow-Origin: null
This response header indicates whether the response can be shared with requesting code from the given origin.
For Instance:
If the request header contains, Origin: https://example.com and Response header contains Access-Control-Allow-Origin: https://example.com
This means that the response will be shared with the request made. This is because the server name in both the Origin and Access-Control-Allow-Origin matches.
If we get back to the first representation of the header where wildcard(*) is used, we can imply that the response can be shared with any of the origin (mentioned in the request header)
Access-Control-Allow-Credentials
Representation
Access-Control-Allow-Credentials: true
This response header tells the browser whether to expose the credentials or not to the frontend-javascript. It will expose the response to front-end js only if value of this header is set to true. When this header is set to true, sensitive information like keys, cookies are also shared as a part of response.
Content Security policy
CSP is a browser security mechanism that aims to mitigate XSS and some other attacks like data injection. It works by restricting the resources (such as scripts and images) that a page can load and restricting whether a page can be framed by other pages (therefore prevents clickjacking).
Note: Clickjacking is an interface-based attack in which a user is tricked into clicking on actionable content on a hidden website by clicking on some other content in a decoy website. The decoy website perfectly overlaps the original website( whose density is reduced to zero, therefore it becomes completely invisible)
To enable CSP, you need to configure your web server to return the Content-Security-Policy HTTP header.
Alternatively, the <meta> element can be used to configure a policy, for example: <meta http-equiv=”Content-Security-Policy” content=”default-src ‘self’; img-src https://*; child-src ‘none’;”>
Representation
Content-Security-Policy: default-src 'self'; img-src *; media-src media1.com media2.com; script-src scripts.example.com
The above snippet can be explained as
A web site admin wants to allow users of an application to include images from any origin as the part of their content, but to restrict audio or video media only to trusted providers. The scripts are allowed only from the specific server upon which the web admin relies as the trusted host.
Here, by default, content is only permitted from the document’s origin, with the following exceptions:
- Images can be loaded from anywhere.
- Media is only allowed from media1.com and media2.com (and not from subdomains of those sites).
- The script is only allowed from scripts.example.com.
Protection against clickjacking using csp
- The following directive will only allow the page to be framed by other pages from the same origin: frame-ancestors ‘self’
- The following directive will prevent framing altogether:frame-ancestors ‘none’
Headers corresponding to Cache Poisioning
This section contains the list of request and response headers who presence can lead to web cache poisioning.
Web cache poisioning is a technique by which an attacker can exploit the cache server to serve malicious content to all the users of that application.
Request headers
- X-Forwareded-Host: The X-Forwarded-Host (XFH) header is a de-facto standard header for identifying the original host requested by the client in the Host HTTP request header. The applications are generally present behind load balancers or CDNs. In that case, X-Forwarded-Host can be used to determine that which host is originally used.
X-forwarded-Host is the de-facto standard, but you might come across different header serving the similar purpose.
- X-host
- X-Forwarded-Server
- X-HTTP-Host-Override
- Forwarded
You will never find these headers as part of the request. But the server might still be using those headers. To find out the presence, you can use PARAMMINER. Param miner is also available as a burp plugin emblazoned with extensive list to bruteforce headers.
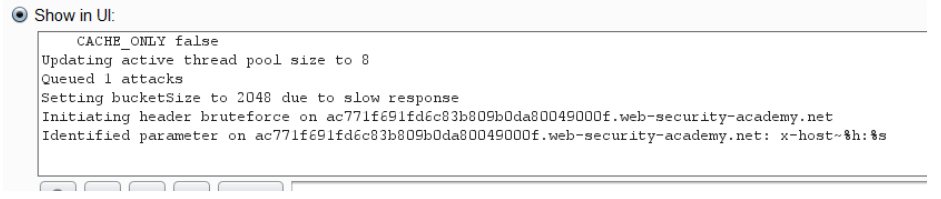
If the URL is dynamically generated in response wrt to the request headers, an attacker can poision the cache and makes it load the content from the the host that is controlled by the attacker.
2. X-forwarded-Proto: The X-Forwarded-Proto (XFP) header is a de-facto standard header for identifying the protocol (HTTP or HTTPS) that a client used to connect to your proxy or load balancer. There might be situation where a http to https request is cacheable. When combined with X-forwarded-host header, an attacker can successfully poison the cache.
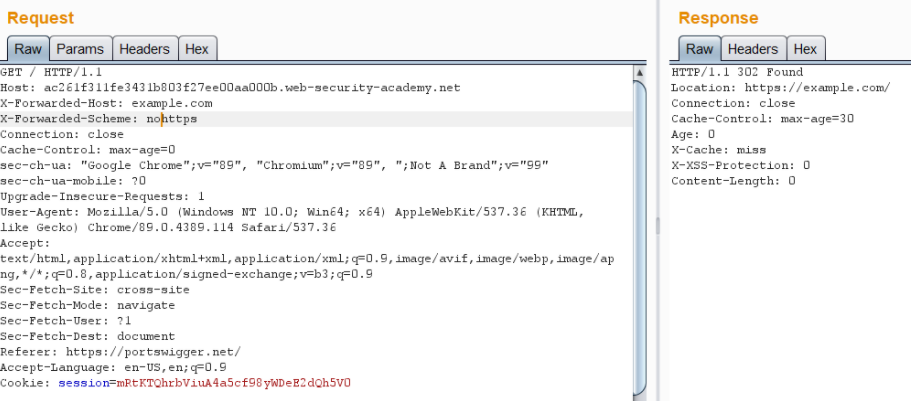
Response headers
One must look for certain headers that can help you confirm the presence of web cache poisioning.
- X-Cache: This header is used when an application is using a CDN to serve its contents. CDN stands for cloud delivery network and its purpose is to cache the contents of a web-server so as to facilitate faster loading.
X-cache: miss # The content was served from the server but now is cached in the CDN X-Cache: hit # The content was served from the CDN.
2. Vary: The vary header specifies a list of additional headers that should be treated as part of cache key even if noramlly they are unkeyd.

With this we come to the end of the post. I hope you enjoyed reading about the most commonly used headers under different . Also, you might have got insights on how important is the header configuration.
See you in the next one! Until then, happy learning 🙂
References
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers



{kind=link}